Clickhouse Overview
table engine
- MergeTree
SQL
create table:
CREATE TABLE helloworld.my_first_table
(
user_id UInt32,
message String,
timestamp DateTime,
metric Float32
)
ENGINE = MergeTree()
PRIMARY KEY (user_id, timestamp)insert:
INSERT INTO helloworld.my_first_table (user_id, message, timestamp, metric) VALUES
(101, 'Hello, ClickHouse!', now(), -1.0),
(102, 'Insert a lot of rows per batch', yesterday(), 1.41421),
(102, 'Sort your data based on your commonly-used queries', today(), 2.718),
(101, 'Granules are the smallest chunks of data read', now() + 5, 3.14159)Each insert into a
MergeTreetable causes a part to be created in storage.
materialized views
CREATE TABLE analytics.hourly_data
(
`domain_name` String,
`event_time` DateTime,
`count_views` UInt64
)
ENGINE = NullData will not be stored in this table.
CREATE TABLE analytics.monthly_aggregated_data
(
`domain_name` String,
`month` Date,
`sumCountViews` AggregateFunction(sum, UInt64)
)
ENGINE = AggregatingMergeTree
ORDER BY (domain_name, month)CREATE MATERIALIZED VIEW analytics.monthly_aggregated_data_mv
TO analytics.monthly_aggregated_data
AS
SELECT
toDate(toStartOfMonth(event_time)) AS month,
domain_name,
sumState(count_views) AS sumCountViews
FROM analytics.hourly_data
GROUP BY
domain_name,
monthTTL(Time-to-live)
When TTL is overdue
- Removing old data: no surprise, you can delete rows or columns after a specified time interval
- Moving data between disks: after a certain amount of time, you can move data between storage volumes - useful for deploying a hot/warm/cold architecture
- Data rollup: rollup your older data into various useful aggregations and computations before deleting it
deduplication strategies
- ReplacingMergeTree:在合并时删除重复行
- CollapsingMergeTree
- 查询时合并:
SELECT * FROM table FINAL - 手动触发合并:
OPTIMIZE TABLE table
ReplacingMergeTree
SELECT *
FROM hackernews_rmt
┌─id─┬─author──┬─comment─────────┬─views─┐
│ 2 │ ch_fan │ This is post #2 │ 0 │
│ 1 │ ricardo │ This is post #1 │ 0 │
└────┴─────────┴─────────────────┴───────┘
┌─id─┬─author──┬─comment─────────┬─views─┐
│ 2 │ ch_fan │ This is post #2 │ 200 │
│ 1 │ ricardo │ This is post #1 │ 100 │
└────┴─────────┴─────────────────┴───────┘SELECT *
FROM hackernews_rmt
FINAL
┌─id─┬─author──┬─comment─────────┬─views─┐
│ 2 │ ch_fan │ This is post #2 │ 200 │
│ 1 │ ricardo │ This is post #1 │ 100 │
└────┴─────────┴─────────────────┴───────┘CollapsingMergeTree
CREATE TABLE hackernews_views (
id UInt32,
author String,
views UInt64,
sign Int8
)
ENGINE = CollapsingMergeTree(sign)
PRIMARY KEY (id, author)sign Int8 用于标记数据版本,值为 1 或 -1
添加一行数据:
INSERT INTO hackernews_views VALUES
(123, 'ricardo', 0, 1)更新这行数据,插入两行:一行取消现有行(只需主键相同?),另一行包含新状态:
INSERT INTO hackernews_views VALUES
(123, 'ricardo', 0, -1),
(123, 'ricardo', 150, 1)SELECT * FROM hackernews_views
┌──id─┬─author──┬─views─┬─sign─┐
│ 123 │ ricardo │ 0 │ -1 │
│ 123 │ ricardo │ 150 │ 1 │
└─────┴─────────┴───────┴──────┘
┌──id─┬─author──┬─views─┬─sign─┐
│ 123 │ ricardo │ 0 │ 1 │
└─────┴─────────┴───────┴──────┘查询最新的行
SELECT *
FROM hackernews_views
FINAL
┌──id─┬─author──┬─views─┬─sign─┐
│ 123 │ ricardo │ 150 │ 1 │
└─────┴─────────┴───────┴──────┘Dictionaries
字典放在内存中,省去了表关联的性能损耗
CREATE DICTIONARY dict_name
(
... -- attributes
)
PRIMARY KEY ... -- complex or single key configuration
SOURCE(...) -- Source configuration
LAYOUT(...) -- Memory layout configuration
LIFETIME(...) -- Lifetime of dictionary in memoryrecommend layouts:
- flat: UInt64 key, max 500000 row
- hashed: Uinx64 key, no row size limit
- complex_key_hashed
支持分层字典(树状),可用于机构树,The dictGetHierarchy function allows you to get the parent chain of an element.
index
主键
- 表中的数据根据主键的字典序存储
- 一张表只能有一个主键
- 支持主键重复
granule(颗粒)
Clickhouse 读取数据的最小单位
主索引
主索引根据每个 granule 的第一行创建,存放在内存中。在查询时,二分搜索主索引。值为 granule 的序号。
每个 part 拥有独立的主索引
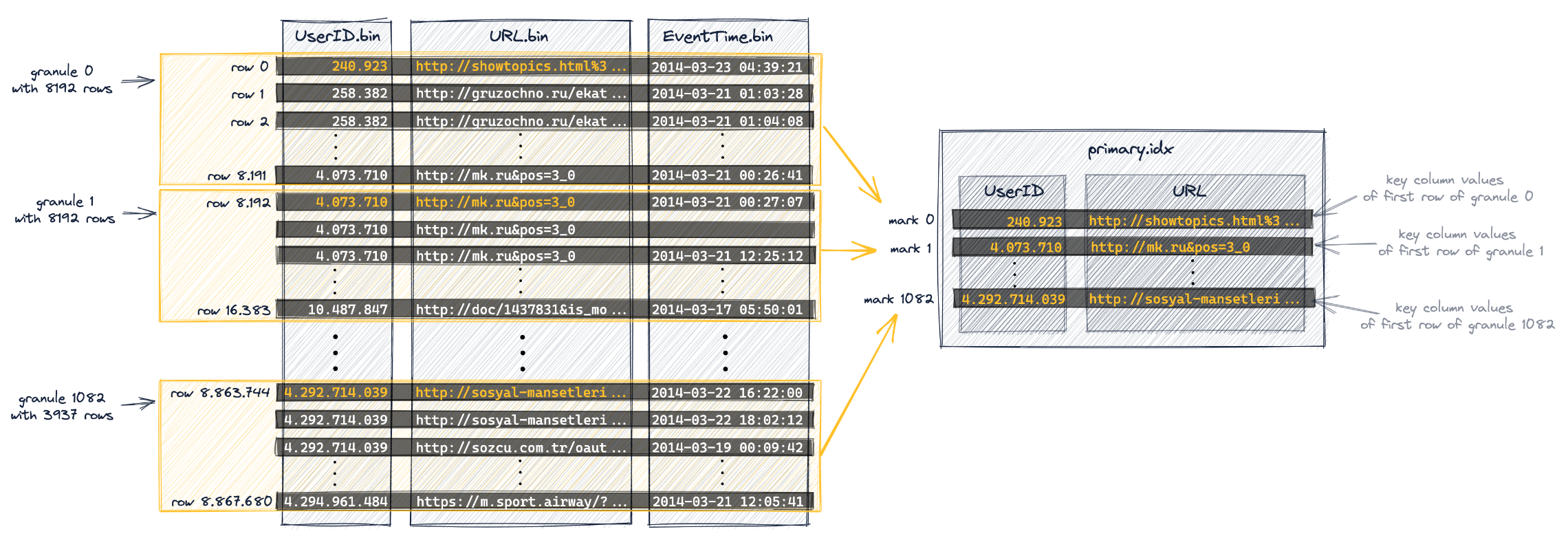
当使用复合主键的时候,对于主键的第一个列筛选时,使用二分搜索;对于其他列筛选,使用通用排除搜索算法(遍历)。
在使用通用排除搜索算法时,复合主键的顺序十分重要,遵循基数从小到大的原则(count(distinct),如 isTrue, userId, urlId),这种排序也有助于加快插入速度,提升数据压缩比。
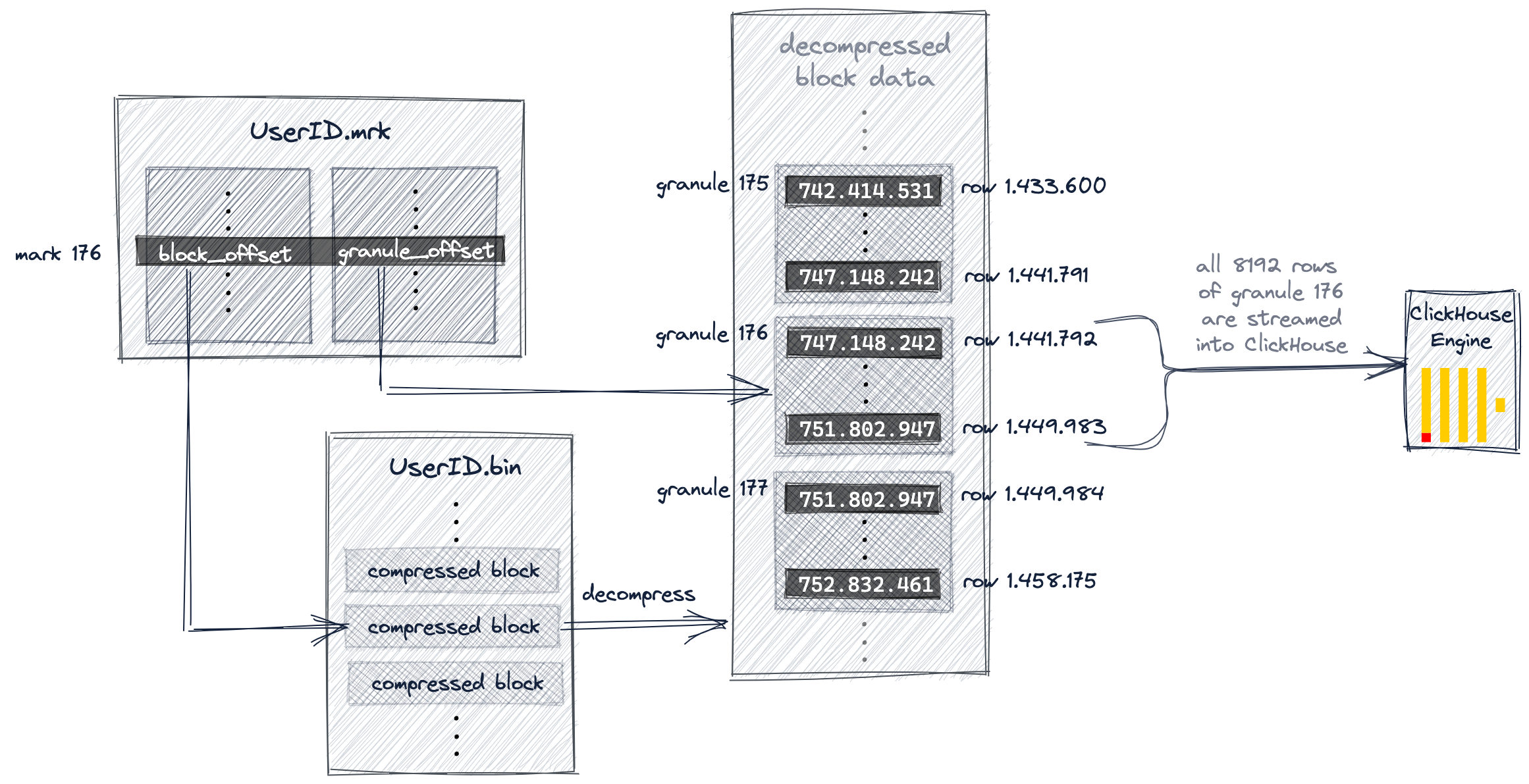
标记文件(.mrk)
每个列对应一个标记文件,用于存储表中所有 granule 的物理位置
为什么主索引不直接包含索引标记对应的颗粒的物理位置?
因为 ClickHouse 的设计规模非常大,所以磁盘和内存的高效利用非常重要。主索引文件需要适合主存。对于我们的示例查询,ClickHouse 使用主索引并选择可能包含与我们的查询匹配的行的单个颗粒。仅对于该一个颗粒,ClickHouse 才需要物理位置,以便流式传输相应的行以进行进一步处理。
投影 projection
投影相当于更智能的物化视图,物化视图基本等同于新建表,投影新增的数据保存在原表的分区目录中,当执行 Select 语句的时候,能根据查询范围,自动匹配最优的 Projection 提供查询加速。
投影并不能加速 order by 过程,即便查询语句的 order by 顺序与投影的 order by 顺序匹配
数据跳过索引
Best Practice
- not
Nullbut default value - 10,000 to 100,000 per inserting batch; 1 second per batch(not for async inserting)
- 分区小于 1000
Functions
- regular functions
- aggregate functions
List of Aggregate Functions
配置
ClickHouse Keeper 或 zeookeeper 推荐生产环境单独部署 4GB
对于少量数据(最多约 200 GB 压缩数据),最好使用与数据量一样多的内存。对于大量数据以及处理交互式(在线)查询时,您应该使用合理数量的 RAM(128 GB 或更多),以便热数据子集适合页面缓存。即使每台服务器的数据量约为 50 TB,与 64 GB 相比,使用 128 GB RAM 也能显着提高查询性能。
如果您的系统 RAM 小于 16 GB,您可能会遇到各种内存异常,因为默认设置与此内存量不匹配。建议的 RAM 量为 32 GB 或更多。您可以在具有少量 RAM(甚至具有 2 GB RAM)的系统中使用 ClickHouse,但它需要额外的调整并且可以以较低的速率进行摄取。