Xtransfer 专场
boolean isOdd(int i , Integer j)和boolean isOdd(Integer i , int i)会构成重载吗?如果传 int 类型和包装类型会调用哪个方法?编译期错误还是运行时错误?具体报什么错?如果入参是两个int类型呢?
如果传入 int 类型和包装类型,会调用方法 1;
如果传入包装类型和 int 类型,会调用方法 2;
如果传入 2 个 int 类型,会报编译期错误,Ambiguous method call,模糊的方法调用。
完全平衡二叉树,写前序遍历和中序遍历。如果不使用递归怎么写?
树节点定义:
class TreeNode {
public int val;
public TreeNode left;
public TreeNode right;
public TreeNode(int val) {
this.val = val;
}
}递归方式前序遍历:
public void preOrder(TreeNode node) {
if (node == null) {
return;
}
System.out.println(node.val);
preOrder(node.left);
preOrder(node.right);
}递归方式中序遍历:
public void middleOrder(TreeNode node) {
if (node == null) {
return;
}
middleOrder(node.left);
System.out.println(node.val);
middleOrder(node.right);
}非递归前序遍历:
public void preOrder(TreeNode node) {
Deque<TreeNode> stack = new LinkedList<>();
while (node != null || stack.size() > 0) {
while (node != null) {
System.out.println(node.val);
stack.push(node);
node = node.left;
}
if (stack.size() > 0) {
node = stack.pop().right;
}
}
}非递归中序遍历:
public void middleOrder(TreeNode node) {
Deque<TreeNode> stack = new LinkedList<>();
while (node != null || stack.size() > 0) {
while (node != null) {
stack.push(node);
node = node.left;
}
if (stack.size() > 0) {
node = stack.pop();
System.out.println(node.val);
node = node.right;
}
}
}用多线程做过什么?
主要是使用线程池做过并发的数据库查询,有接口需要整合返回多个不同数据表的信息,不同这些查询都是互相独立的,不需要做关联操作,所以写了一个线程池来并发查询,使用countdownlatch来通知主线程最后一个查询线程执行完毕。
同时大批量的数据导出和数据导入也使用了多线程。
多线程之间的同步机制有哪些?
1 互斥量(mutex):互斥量本质上是一把锁,在访问共享资源前对互斥量进行加锁,在访问完成后释放互斥量上的锁。在 Java 中的实现,如synchronized
2 信号量(semaphore):互斥量只能用于一个资源的互斥访问,信号量可以实现多个同类资源的多线程互斥和同步。当信号量为单值信号量时,也可以完成一个资源的互斥访问。
3 读写锁:读写锁与互斥量类似,不过读写锁允许更高的并行性。互斥量要么是锁住状态要么是不加锁状态,而且一次只有一个线程可以对其加锁。
4 条件变量:条件变量与互斥量一起使用时,允许线程以无竞争的方式等待特定的条件发生。条件本身是由互斥量保护的。线程在改变条件状态前必须首先锁住互斥量,其它线程在获得互斥量之前不会察觉到这种改变,因此必须锁定互斥量以后才能计算条件。在 Java 中的实现:condition
Java 有哪些锁?reentrantlock的优点是什么?
按照不同的分类,分为
- 公平锁/非公平锁
- 乐观锁/悲观锁
- 独享锁/共享锁
- 互斥锁/读写锁
- 可重入锁/不可重入锁
reentrantlock是可重入锁,同一线程在多次进入被锁代码块时,无需重复获取锁。可重入锁可以在一定程度上避免死锁。
数据库隔离级别,RC和RR分别说一下
从低到高:
- 读未提交:存在脏读、不可重复读、幻读问题
- 读已提交:存在不可重复读、幻读问题
- 可重复读:存在幻读问题
- 串行化
什么是不可重复读
分布式的CAP说一下
Eureka 保证的是CAP的哪两个
Eureka 保证的是 AP,因为 Eureka 的每个节点都是独立的,部分节点挂掉不会影响整体服务。 除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
- Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用)
- 当网络稳定时,当前实例新的注册信息会被同步到其它节点中
CP和AP在某个机器宕机的情况下会有什么反映,比如有五台机器,有一台宕机了,CP和AP的策略是什么
CP的代表性中间件 zookeeper,在master宕机时会进行重新选举,在选举期间整个服务不可用 AP的代表性产品 Eureka,一台宕机后会不会影响使用,但该台机器上面的部分数据可能会丢失
什么时候应该用 CP,什么时候应该用 AP
如果业务需求需要原子读写,使用 CP 如果业务需求允许最终一致性,或当外部故障时要求系统继续运行,使用 AP
CMS 和 G1 的区别,各自的优势
CMS 会尽量减少垃圾回收的总时间,使用严格控制时间的应用,例如 ES G1 可以大致控制每次垃圾回收的时间,将 old gc 时间分散,适合大内存应用
CMS 优点:
- 支持并发收集.
- 低停顿,因为 CMS 可以控制将耗时的两个 stop-the-world 操作保持与用户线程恰当的时机并发执行,并且能保证在短时间执行完成,这样就达到了近似并发的目的
CMS 缺点:
- CMS 对 CPU 资源非常敏感,在并发阶段虽然不会导致用户线程停顿,但是会因为占用了一部分 CPU 资源,如果在 CPU 资源不足的情况下应用会有明显的卡顿。
- 无法处理浮动垃圾:在执行并发清理步骤时,用户线程也会同时产生一部分可回收对象,但是这部分可回收对象只能在下次执行清理是才会被回收。如果在清理过程中预留给用户线程的内存不足就会出现‘Concurrent Mode Failure’,一旦出现此错误时便会切换到 SerialOld 收集方式。
- CMS 采用标记-清除算法,清理后会产生大量的内存碎片,当有不足以提供整块连续的空间给新对象 / 晋升为老年代对象时又会触发 FullGC。
G1 优点:
- 并行与并发:G1 充分发挥多核性能,使用多 CPU 来缩短 Stop-The-world 的时间,
- 分代收集:G1 能够自己管理不同分代内已创建对象和新对象的收集。
- 空间整合:G1 从整体上来看是基于‘标记-整理算法’实现,从局部(相关的两块Region)上来看是基于‘复制’算法实现,这两种算法都不会产生内存空间碎片。
- 预测的停顿:它可以自定义停顿时间模型,可以指定一段时间内消耗在垃圾回收商的时间不大于预期设定值。
IOC 时,如何解决 bean 的循环依赖
Spring 中存在三级缓存:
-
singletonObjects: 一级缓存,存储单例对象,Bean 已经实例化,初始化完成
-
earlySingletonObjects: 二级缓存,存储 singletonObject,这个 Bean 实例化了,还没有初始化
-
singletonFactories: 三级缓存,存储 singletonFactory。
-
Spring是通过递归的方式获取目标bean及其所依赖的bean的;
-
Spring实例化一个bean的时候,是分两步进行的,首先实例化目标bean,然后为其注入属性。
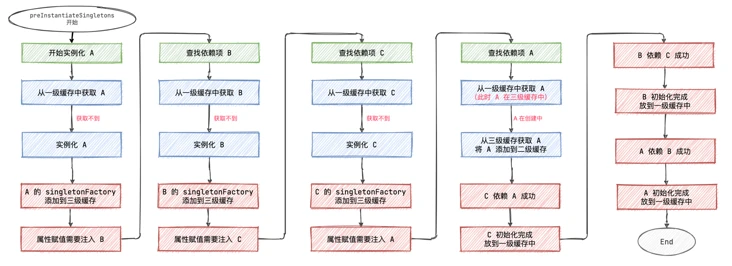
https://zhuanlan.zhihu.com/p/84267654
BeanFactoryPostProcessor 的作用
BeanFactoryPostProcessor 是spring初始化bean的扩展点,在容器实际实例化任何其它的bean之前,读取配置元数据,并可修改 Bean 定义
BeanPostProcessor 的作用
BeanPostProcessor 可以在 spring 容器实例化 bean 之后,在执行 bean 的初始化方法前后,添加一些自己的处理逻辑
依赖注入的方式有哪些?
- Setter 注入
- 构造器注入
- 注解注入
项目中重构迁移的操作是怎么解决的,数据如何迁移?
Redis 的数据扩容怎么实现
https://cloud.tencent.com/developer/article/1604780
队列的实现原理
https://www.cnblogs.com/NeilZhang/p/8623207.html
队列数组长度不够了,如何操作?是移除头部元素?还是扩容?还是循环数组?
分布式事务的思想?如何实现?2PC是什么?TCC怎么实现补偿机制?3PC是什么?
https://segmentfault.com/a/1190000040321750
如果有相互调用的系统,位于一个分布式事务中,一个 系统宕机了,整个分布式事务如何进行回滚?逻辑怎么进行?
CountDown(闭锁)怎么实现线程阻塞?最后一同执行,怎么保证同时唤醒操作?
HashMap 的 put 方法详解 ,size方法是怎么操作的?
synchronized 和 lock 的区别?