Analyzing data 分词
Two processes happen during the analysisi process: tokenization and normalization.
Tokenization
Tokenization is the process of breaking text into tokens based on a set of rules.
Normalization
Normalization is a process of reducing(stemming) tokens to root words or creating synonyms for them. E.g.:
- The
pepperstoken can be stemmed to create alternate words likecapsicum - The
Pipertoken can be stemmed to produceBagpiper
Anatomy of an analyzer
Tokeniztion and normalization are carried out by three software components - character filters, tokenizers, and token filters - which essentially work together as an analyzer module.
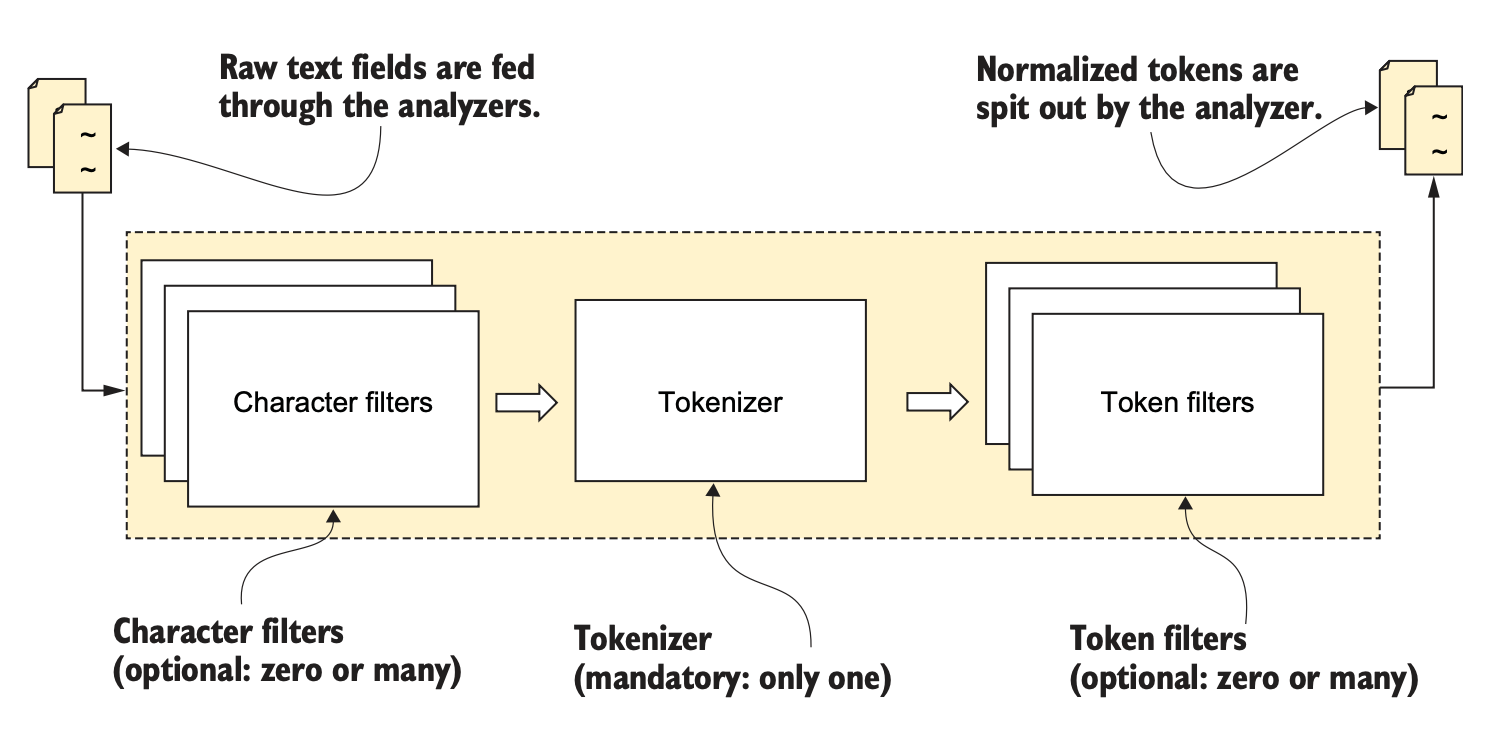
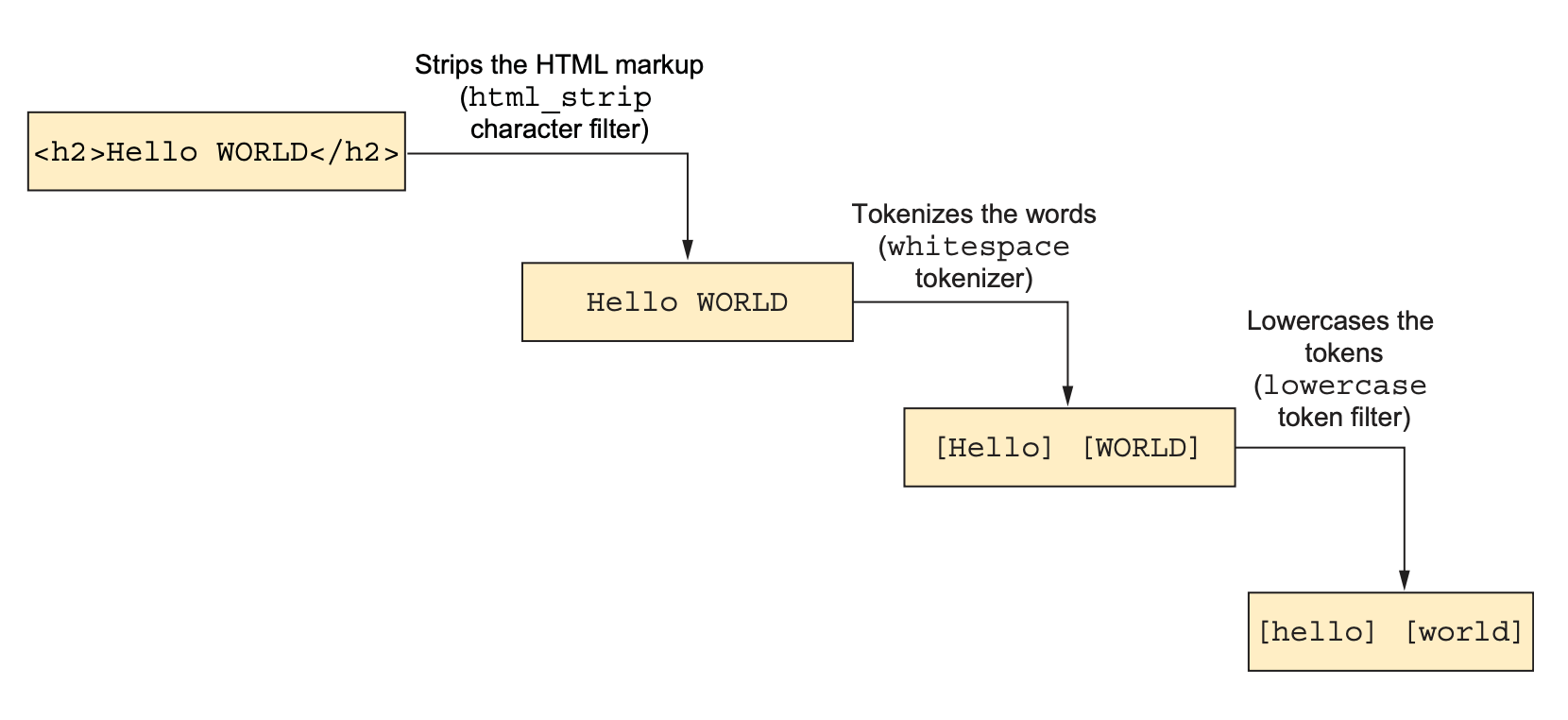
- Character filters: remove unwanted characters, replace text with other text (e.g., Greek letters with the equivalent English words)
- Tokenizers: split
textfields into words using a delimiter such as whitespace. Every analyzer must have one and only one tokenizer. - Token filters: performm further processing on tkens produced by tokenizers. For example, token filters can change case, create synonyms, provide root words(stem), produce n-grams and shingles, and so on.
Custom analyzers
PUT index_with_custom_analyzer
{
"settings": {
"analysis": {
"analyzer": {
"custom_analyzer": {
"type": "custom",
"char_filter": ["charfilter1", "charfilter2"],
"tokenizer": "standard",
"filter": ["tokenfilter1", "tokenfilter2"]
}
}
}
}
}